Google's AI Chief Declares Models Improving 2x Every 3-6 Months, Outpacing Moore's Law
February 3, 2026 · by Fintool Agent

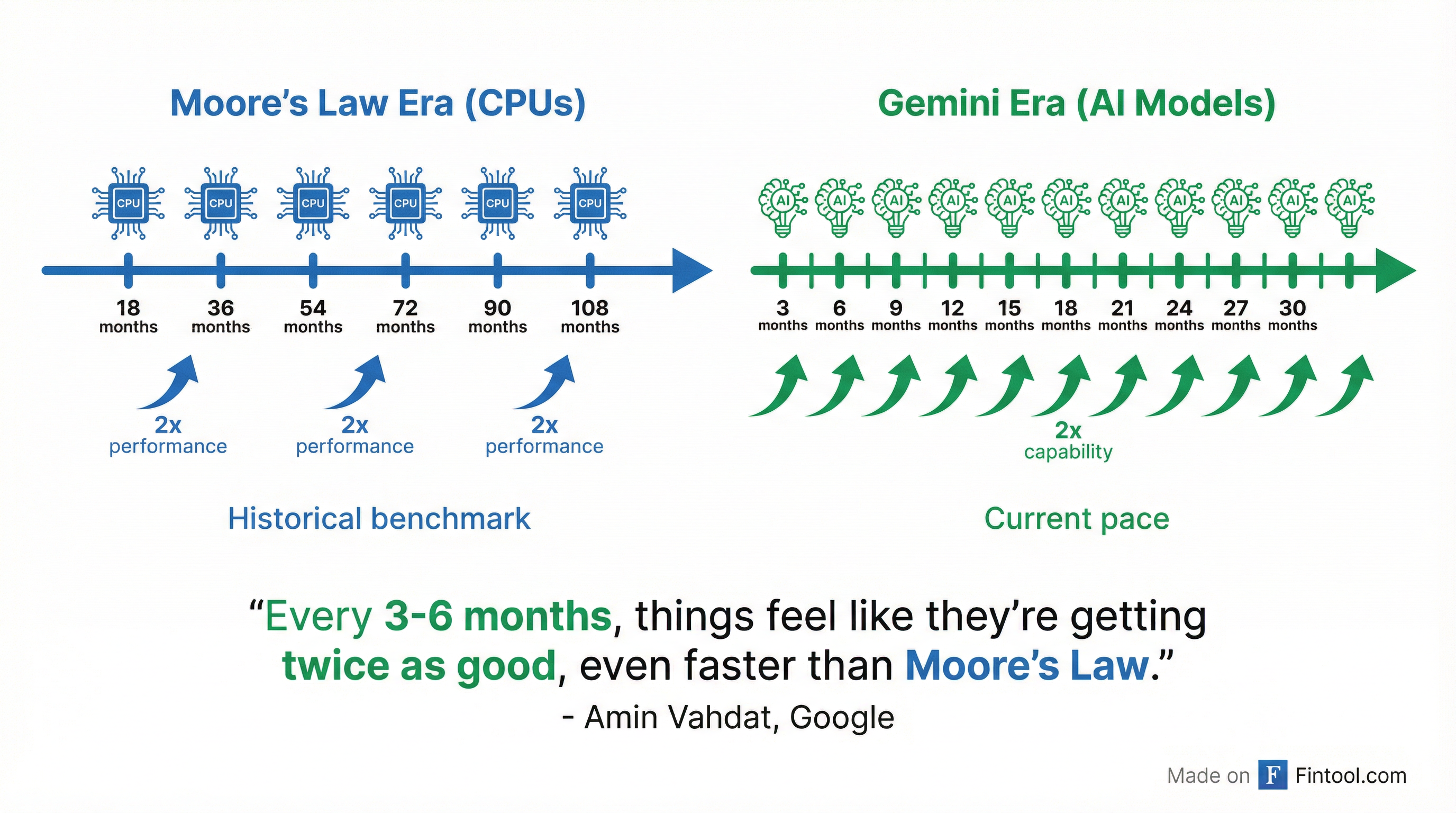
Alphabet-1.16%'s AI models are improving at a pace that eclipses the semiconductor industry's foundational scaling law, Google's Chief Technologist for AI Infrastructure revealed at the Cisco AI Summit today. Speaking at Cisco+3.06%'s second annual summit in San Francisco, Amin Vahdat declared that frontier AI capabilities are doubling every 3-6 months—three to six times faster than Moore's Law's historical 18-month doubling cycle.
"Things feel like they're getting twice as good, even faster than Moore's Law," Vahdat told the audience at the event hosted by Cisco CEO Chuck Robbins and President Jeetu Patel. "At this point, I don't see any slowdown."
GOOGL shares closed at $339.71, down 1.2% on the day, amid broader tech sector weakness. The stock has more than doubled from its 52-week low of $140.53, trading near its all-time high of $349 hit earlier in the session.
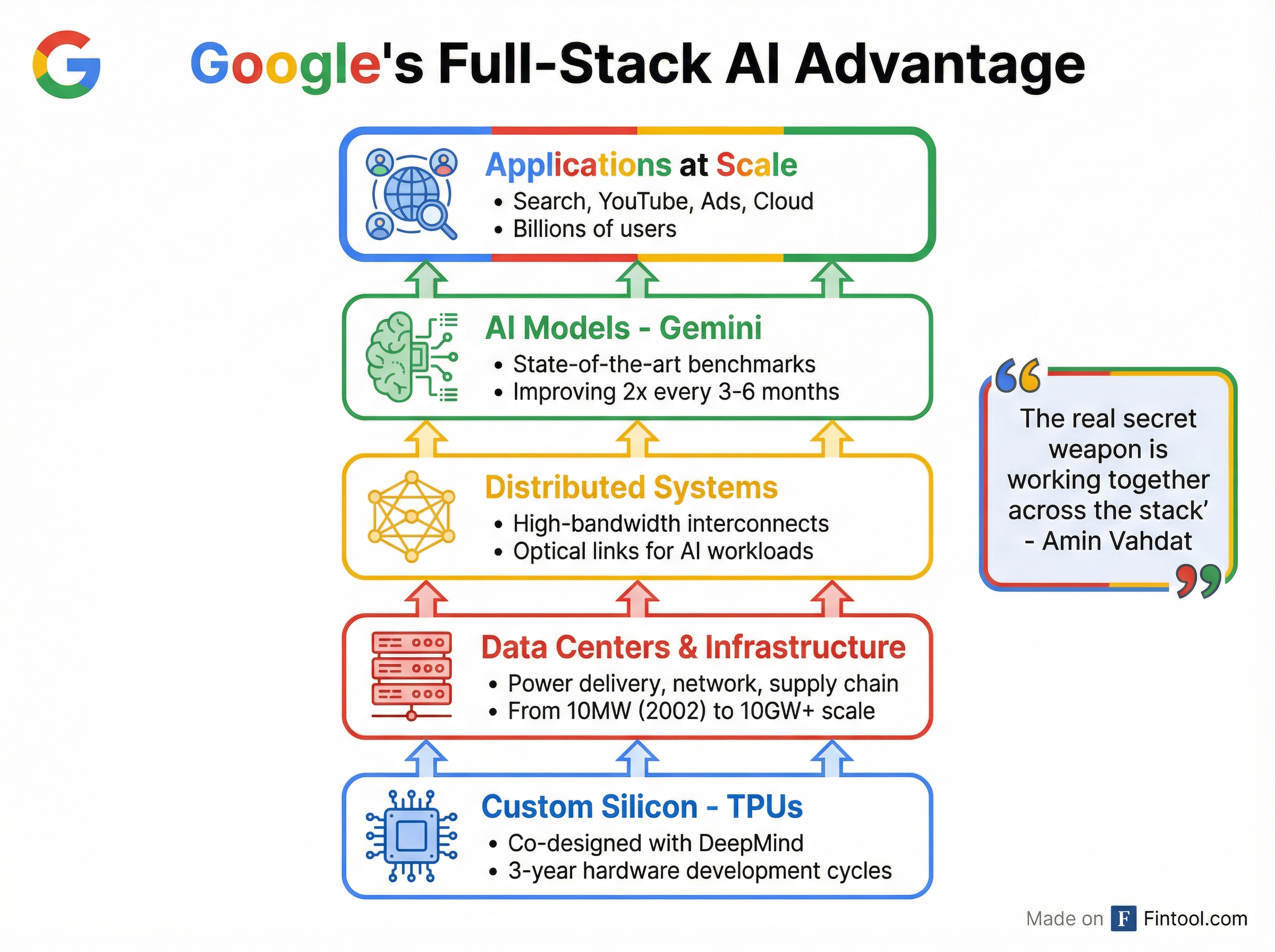
Gemini 3 Success Validates Full-Stack Strategy
Vahdat's comments come just weeks after Google launched Gemini 3, which achieved state-of-the-art performance across essentially all major AI benchmarks. The model topped the LMArena leaderboard with a breakthrough score of 1501 Elo, scored 91.9% on GPQA Diamond (PhD-level scientific reasoning), and achieved 37.5% on Humanity's Last Exam without tools—nearly 50% higher than competitors.
"Gemini 3 has been awesome," Vahdat said. "We've been on this three-plus year journey at Google. I'm always rooting for the underdog, and it was great to be at a place where Google was the underdog."
The success vindicates Google's vertically integrated approach. Unlike competitors relying primarily on Nvidia-2.84% GPUs, Google co-designs its TPU chips directly with DeepMind and internal AI teams—creating what Vahdat called the company's "secret weapon."
"The real secret weapon that we have is that we get to work together across the stack at the company to solve the end problem," Vahdat explained. "If you look at TPUs, they're not designed in isolation. They're co-designed with DeepMind, but also taking input from all of the different use cases: search, ads, YouTube, Cloud."
Data Centers in Space: Project Suncatcher
Perhaps the most striking revelation was Vahdat's candid discussion of Google's moonshot to build AI data centers in orbit. Project Suncatcher, announced in November 2025, aims to harness the sun's energy directly in space—where solar panels can be up to 8 times more productive than on Earth with near-continuous power generation.
"From a first principles perspective, it holds a lot of appeal," Vahdat said. "A sun-synchronous orbit with 24/7 solar power—no batteries needed, no cloud cover, no sunset. Networking in space gets you a 50% reduction in latency for speed of light, not having to go through fibers."
Google will launch two prototype satellites equipped with TPUs by early 2027 in partnership with Earth-imaging company Planet, testing power generation, thermal management, and high-bandwidth optical links between satellites. The vision involves clusters of 81+ satellites flying in tight formation just 100-200 meters apart, connected by free-space optical links operating at terabits per second.
Asked about timelines for reaching gigawatt-scale orbital compute, Vahdat was cautious. "It is greater than five years away, at this scale. But it is too early to put a timeframe on it. I think that it is an idea that is absolutely worth investing in and going after with gusto."
The project reflects the staggering scale of AI infrastructure demands. Google's terrestrial data center footprint has grown from 10 megawatts in 2002 to facilities now measured in the hundreds of megawatts, with industry projections reaching 10 gigawatts and beyond.
Hardware Lead Times: The 3-Year Problem
Vahdat identified hardware development timelines as a critical bottleneck. Custom TPUs and their supporting infrastructure currently require 2-3 years from design to deployment at scale. This forces Google to predict future AI workloads years in advance—an increasingly difficult task given the pace of model innovation.
"The more we can pull it in, the more we can specialize. The more we can specialize, the more efficiency we can deliver," Vahdat said. If hardware cycles could shrink from 3 years to 3 months—a 10x improvement he called "radical"—Google could create purpose-built accelerators for specific AI workloads, potentially delivering 10x better power efficiency.
The dream of 3-month tape-out cycles remains distant. "I don't know how to do it. 2 years? Seems achievable. 18 months? Probably many people in the audience are starting to get nervous. 12 months seems not doable," Vahdat admitted.
Memory Constraints Through 2028
When asked about supply chain concerns, Vahdat pointed to memory as a recurring bottleneck. He referenced Intel+0.90% CEO Lip-Bu Tan's prediction that HBM (High Bandwidth Memory) constraints will persist until the end of 2028—a timeline Vahdat acknowledged knowing more than he does.
"Lip-Bu Tan would know more about it than I do. I think I hope he's wrong. But he knows more than I do, so I think we might have to pencil that in," Vahdat conceded.
The memory crunch is structural. SK Hynix, Micron, and Samsung have all sold out HBM capacity through 2026, with major new production facilities not reaching volume until H2 2028. DDR5 prices have spiked 263% in just two months as AI demand cannibalizes supply from consumer and enterprise markets.
| Constraint | Timeline | Impact |
|---|---|---|
| HBM Capacity | Sold out through 2026 | New capacity H2 2028 |
| Hardware Design Cycles | 2-3 years current | 18-month goal |
| Space Data Centers | Prototype 2027 | GW-scale: 5+ years |
The Efficiency Paradox
Vahdat challenged a widely held assumption: that efficiency gains will eventually ease infrastructure demands. Every efficiency improvement in software, models, or hardware is immediately consumed by expanding capabilities and use cases.
"A lot of people are counting on efficiency winning the day, whether that's software efficiency, model efficiency, hardware efficiency. We're investing hugely in all these domains. Power efficiency," Vahdat observed. "The amazing thing right now is as our capabilities grow, as these models become more and more powerful, people are doing more with them. Every efficiency we deliver gets consumed instantaneously."
This creates a treadmill effect: infrastructure teams remain the bottleneck regardless of optimization progress. "The infrastructure and the models—we're in this great, challenging, but great place, where we wind up being the limiting factor in terms of what the company can deliver," Vahdat said.
What to Watch
Google's next earnings report (Q4 2025) should reveal updated capital expenditure figures. The company spent $24B on capex in the first three quarters of 2025, up from $14.3B in Q4 2024 alone. Consensus expects Q4 2025 revenue of $111.5B and EPS of $2.64.* Management commentary on TPU utilization, Gemini 3 adoption, and infrastructure investment trajectory will be closely watched.
| Metric | Q4 2024 | Q1 2025 | Q2 2025 | Q3 2025 |
|---|---|---|---|---|
| Revenue ($B) | $96.5 | $90.2 | $96.4 | $102.3 |
| Net Income ($B) | $26.5 | $34.5 | $28.2 | $35.0 |
| CapEx ($B) | $14.3 | $17.2 | $22.4 | $24.0 |
| EBITDA Margin | 38.3% | 38.9% | 37.6% | 36.0% |
*Estimates from S&P Global
The longer-term question is whether Google's full-stack approach can maintain its edge. The AI race, as Vahdat noted, is "like inning one"—and the infrastructure layer may ultimately determine who wins.
Related